Ollama with Llama3 and Code Interpreter

Search for a command to run...
No comments yet. Be the first to comment.
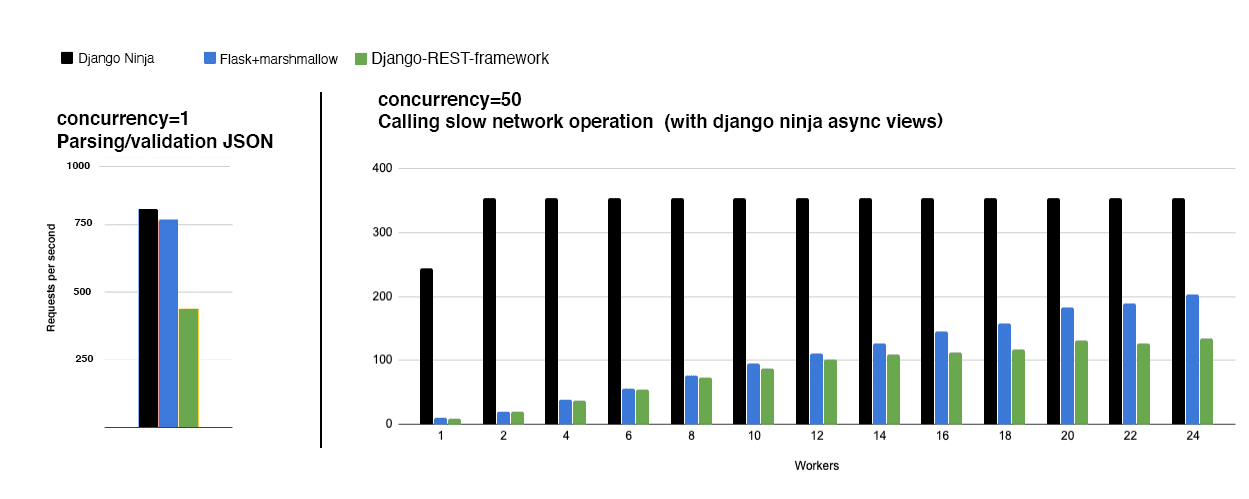
Our async django production experience
“uv” is a newish Python package installer and resolver. It is a nice balance between the simplicity of plain old venv, and the complexity of poetry. The team behind so far, had made the right opinionated choices and I believe it will continue to grow...
Hyperscript is a really fun way to add little event-driven scripts to your web application. It is one of the best ways to enforce locality of behavior in a hypermedia-first application. It also solves a bunch of problems with async behavior in native...
One of the projects I have built is a long-standing retrieval-augmented generation (RAG) application. Documents are saved in a database, chunked into a reasonable amount of text that a large language model (LLM) can handle, and turned into numerical ...

I've got some cool tools—both AI and non-AI, open-source—that I absolutely love using on my local machine. One tool that I really wanted to move to the cloud, is the screenshot-to-code tool. It makes life so much easier for designers to developers ha...

I try to run an experiment once a week with open-source LLMs. This week experiment was using Llama3 via Ollama and AgentRun to have an open-source, 100% local Code Interpreter.
The idea is, give an LLM a query that is better answered via code execution instead of its training. Run the code in AgentRun, then return the answer to the user. It is more or less a proof of concept, that can be expanded on with additional tools that an LLM can use.
For this experiment, I had Ollama installed and running as well as the AgentRun API. My goal was use code generated by an LLM it to answer some questions that normally an LLM would struggle with. Like, what is 12345 * 54321? Or what is the largest prime number under 1000?
The full code is available here: https://jonathan-adly.github.io/AgentRun/examples/ollama_llama3/
If you don't have Ollama installed, first install it from here. Then, run a test query to make sure everything is working.
curl -X POST http://localhost:11434/api/generate -d '{
"model": "llama3",
"prompt":"What is 1+1?"
}'
Next, install AgentRun and have its REST API running. You will need docker installed to use docker-compose.
git clone https://github.com/Jonathan-Adly/agentrun
cd agentrun/agentrun-api
cp .env.example .env.dev
docker-compose up -d --build
And again, let's make a test request to make sure everything is running correctly.
curl -X GET http://localhost:8000/v1/health/
# {"status":"ok"}
Next, we will run a Python script that will be our starting point to run queries against Llama3 with Agentrun.
python -m venv agentrun-venv
# windows: .\agentrun-venv\Scripts\activate
source agentrun-venv/bin/activate
# windows: New-Item main.py -type file
touch main.py
pip install requests json_repair
In the file, we will start off by importing the necessary libraries. We'll need json for handling data and requests for making HTTP calls. We’re also using a cool library called json_repair just in case our JSON data decides to act up and we need to fix it on the fly. This is especially the case if use 8B version of Llama3 where the JSON sometimes is slightly broken.
import json
import json_repair
import requests
We've crafted a simple function execute_python_code. This function is pretty straightforward—it sends a Python code snippet to a code execution environment provided by AgentRun and fetches the output.
Here's a quick peek at how this works:
def execute_python_code(code: str) -> str:
code = json.dumps({"code": code})
response = requests.post(
"http://localhost:8000/v1/run/",
data=code,
headers={"Content-Type": "application/json"},
)
print(code)
output = response.json()["output"]
return output
We basically format the code snippet into JSON, send it off to our localhost where the magic happens, and get back the result. You can read more about how AgentRun works here.
Next, we would use this function as our basis for defining the tool that we want Llama3 to use. Here is what this looks like.
tools = [
{
"type": "function",
"function": {
"name": "execute_python_code",
"description": """Sends a python code snippet to the code execution environment and returns the output.
The code execution environment can automatically import any library or package by importing.
The code snippet to execute must be a valid python code and must use print() to output the result.""",
"parameters": {
"type": "object",
"properties": {
"code": {
"type": "string",
"description": "The code snippet to execute. Must be a valid python code. Must use print() to output the result.",
},
},
"required": ["code"],
},
},
},
]
Lastly, we will set up our model here. We can use the base Llama3 or any of the finetunes provided by the community. For the sake of experimentations, I ran my experiment using Dolphin-llama3 8b finetune.
# Ollama dolphin-llama3 page: https://ollama.com/library/dolphin-llama3
MODEL = "dolphin-llama3"
Moving on to the cooler element—integration with the Ollama and Llama3.
Here’s a how the query processing and tool selection works:
def generate_full_completion(prompt: str, model: str = MODEL) -> dict[str, str]:
# setting up the parameters including our model
params = {
"model": model,
"prompt": prompt,
"stream": False,
# seed and temperature for deterministic output
"temperature": 0,
"seed": 123,
# format is JSON, since we are interested in tools/function calling
"format": "json",
}
# making the post request and handling responses
try:
response = requests.post(
f"http://localhost:11434/api/generate",
headers={"Content-Type": "application/json"},
data=json.dumps(params),
timeout=60,
)
return json_repair.loads(response.text)
except requests.RequestException as err:
return {"error": f"API call error: {str(err)}"}
Now, that we have everything setup. We will simply use a prompt to nudge the model toward using our execute_python_code tool for its outputs.
def get_answer(query: str) -> str:
functions_prompt = f"""
You have access to the following tools:
{tools}
You must follow these instructions:
If a user query requires a tool, you must select the appropriate tool from the list of tools provided.
Always select one or more of the above tools based on the user query
If a tool is found, you must respond in the JSON format matching the following schema:
{{
"tools": {{
"tool": "<name of the selected tool>",
"tool_input": <parameters for the selected tool, matching the tool's JSON schema
}}
}}
If there are multiple tools required, make sure a list of tools are returned in a JSON array.
If there is no tool that match the user request, you will respond with empty json.
Do not add any additional Notes or Explanations.
User Query: {query}
"""
r_dict = generate_full_completion(functions_prompt)
r_tools = json_repair.loads(r_dict["response"])["tools"]
code = r_tools["tool_input"]["code"]
response = execute_python_code(code)
return response
Finally, when you feed it a query like "what's the 12312 * 321?" the whole system whirls into action, the model figures out which tool and code snippet to use, executes it, and bam! You've got your answer.
Let’s see it in action with a couple of examples:
# 3952152
print(get_answer("what's 12312 *321?"))
# 500
print(get_answer("how many even numbers are there between 1 and 1000?"))
# Paris
print(get_answer("what's the capital of France?"))
We're blending advanced model integration with practical code execution. Whether you're automating tasks, building out a project, or just playing around to see the capabilities, this setup might just be your next go-to.
And, there you go—a delightful mix of Python, APIs, and some AI magic to streamline how you handle and execute code snippets. As always, tweak, tinker, and tailor it to your needs. Happy coding, everyone!